Some of these topics are also described in the book from Stallings used for the A2 course.
Message passing is a form of interaction between two or more processes, which can provide both communication and synchronization: a message can only be received after it has been sent. It can be implemented on distributed systems, shared memory multiprocessors and on uni-processors. The actual function of message passing is usually provided with 2 primitives: send(destination, message) and receive(source, message).
After issuing a send the process can either continue directly (nonblocking) or after the message has been received (blocking). Also a receive can be blocking or non-blocking. Blocking sender and receiver until the message is received is called rendez-vous, it is used in the ADA programming language. Usually the send is nonblocking, allowing the sender to send one or more messages to various destinations as quickly as possible. The receive is usually blocked, as the receiving process needs input data before it can do useful work. Often ways are provided to probe the input queue to see if a message has arrived, before issuing a receive or to time-out a receive.

Addressing can be direct, meaning that source and destination are given as specific identifiers of the involved processes. Senders are often given the possibility to indicate a range of receivers for a message. Receivers can often indicate that they want to receive from any source.
In indirect addressing messages are send to shared data structures consisting of queues that can temporarily hold messages. These queues are called mailboxes, they allow for one-to-one, many-to-one, one-to-many or many-to-many relations between senders and receivers. A many-to-one relation is useful for client/server interaction, the mailbox is then often called a port. A port is usually created by and owned by the server process. For mailboxes, the operating system often has services to create and manage them.
Mailboxes and ports usually have a FIFO queueing strategy. But also queueing based on priority can be used.
Usually variable length messages are provided for. The header of the message contains then source and destination information and a length field. Also a message type field, allowing to discriminate between various types of messages, is usually provided. Control fields may be provided for sequence numbers, priority or pointers to create linked list of messages.
program mutualexclusion; const n = . . . ; (*number of processes*); procedure P(i: integer); var msg: message; begin repeat receive (mutex, msg); < critical section >; send (mutex, msg); < remainder > forever end; begin (* main program *) create_mailbox (mutex); send (mutex, null); parbegin P(1); P(2); . . . P(n); parend end. |
Message passing can be used to enforce mutual exclusion. Left is an example where a set of concurrent processes share a mailbox (mutex). A nonblocking send and a blocking receive is assumed. The message functions as a token that is passed from process to process. If more than one process performs a receive operation than:
The concurrent processes can also be parallel (running on different CPU's) processes, provided they have access to the global mailbox mutex. |
This is described here as an example of a message passing system. Another example is MPI (Message Passing Interface) which is also widely available.
PVM is a de-facto standard system for message passing. Briefly, the principles upon which PVM is based include the following:
The PVM system is composed of two parts. The first part is a daemon program, called pvmd3, which resides on all the computers making up the virtual machine. Pvmd3 is designed so any user with a valid login can install this daemon on a machine. When a user wishes to run a PVM application, he first creates a virtual machine by starting up PVM. The PVM application can then be started from a Unix prompt on any of the hosts. Multiple users can configure overlapping virtual machines, and each user can execute several PVM applications simultaneously.
The second part of the system is a library of PVM interface routines. It contains a functionally complete repertoire of primitives that are needed for cooperation between tasks of an application. This library contains user-callable routines for message passing, spawning processes, coordinating tasks, and modifying the virtual machine.
PVM has been ported to three distinct classes of architecture:
Each of these classes requires a different approach to make PVM exploit the capabilities of the respective architecture. The workstations use TCP/IP to move data between hosts, the distributed-memory multiprocessors use the native message-passing routines to move data between nodes, and the shared-memory multiprocessors use shared memory to move data between the processors.
int tid = pvm_mytid( void )
This routine returns the TID (task identifier) of this process and can be called multiple times. It enrolls this process into PVM if this is the first PVM call.
int info = pvm_exit( void )
This routine tells the local pvmd that this process is leaving PVM. This routine does not kill the process, which can continue to perform tasks just like any other UNIX process.
int numt = pvm_spawn(char *task, char **argv, int flag, char *where, int ntask, int *tids )
This routine starts up ntask copies of an executable file task on the virtual machine. argv is a pointer to an array of arguments to task. The flag argument is used to specify options, and is a sum of:
Value Option Meaning
--------------------------------------------------------------------------
0 PvmTaskDefault PVM chooses where to spawn processes.
1 PvmTaskHost where argument is a particular host to spawn on.
2 PvmTaskArch where argument is a PVM_ARCH to spawn on.
4 PvmTaskDebug starts tasks under a debugger.
8 PvmTaskTrace trace data is generated.
--------------------------------------------------------------------------
On return, numt is set to the number of tasks successfully spawned or an error code if no tasks could be started. If tasks were started, then a vector of the spawned tasks id's is returned in tids; and if some tasks could not be started, the corresponding error codes are placed in the last ntask - numt positions of the vector.
int bufid = pvm_initsend( int encoding )
If the user is using only a single send buffer (and this is the typical case) then this is the only required buffer routine. The new buffer identifier is returned in bufid.
The encoding options are as follows:
Each of the following C routines packs an array of the given data type into the active send buffer. They can be called multiple times to pack data into a single message. Thus, a message can contain several arrays each with a different data type. C structures must be passed by packing their individual elements. There is no limit to the complexity of the packed messages, but an application should unpack the messages exactly as they were packed.
The arguments for each of the routines are a pointer to the first item to be packed, nitem which is the total number of items to pack from this array, and stride which is the stride to use when packing. A stride of 1 means a contiguous vector is packed, a stride of 2 means every other item is packed, and so on. An exception is pvm_pkstr() which by definition packs a NULL terminated character string.
int info = pvm_pkbyte( char *cp, int nitem, int stride ) int info = pvm_pkcplx( float *xp, int nitem, int stride ) int info = pvm_pkdcplx( double *zp, int nitem, int stride ) int info = pvm_pkdouble( double *dp, int nitem, int stride ) int info = pvm_pkfloat( float *fp, int nitem, int stride ) int info = pvm_pkint( int *np, int nitem, int stride ) int info = pvm_pklong( long *np, int nitem, int stride ) int info = pvm_pkshort( short *np, int nitem, int stride ) int info = pvm_pkstr( char *cp ) int info = pvm_packf( const char *fmt, ... )
PVM also supplies a packing routine that uses a printf-like format expression to specify what data to pack and how to pack it into the send buffer. All variables are passed as addresses if count and stride are specified; otherwise, variables are assumed to be values.
For unpacking there are similar routines to get data out of the receiver buffer.
int info = pvm_send( int tid, int msgtag ) int info = pvm_mcast( int *tids, int ntask, int msgtag )
The routine pvm_send() labels the message with an positive integer identifier msgtag and sends it immediately to the process TID. The routine pvm_mcast() broadcasts the message to all tasks specified in the integer array tids (except itself). The tids array is of length ntask.
int bufid = pvm_recv( int tid, int msgtag )
This blocking receive routine will wait until a message with label msgtag has arrived from TID. A value of -1 in msgtag or TID matches anything (wildcard). It then places the message in a new active receive buffer that is created. The previous active receive buffer is cleared unless it has been saved with a pvm_setrbuf() call.
Also a non-blocking and a time-out version of receive are provided. With pvm_probe() the receive queue can be checked to see if messages of certain type or sender have arrived.
Functions which combine packing / sending and receiving / unpacking, are also provided. On multiprocessor systems they can often make better use of the native message passing facilities, so they can work faster

XPVM provides a graphical interface to the PVM console commands and information, along with several animated views to monitor the execution of PVM programs. These views provide information about the interactions among tasks in a parallel PVM program, to assist in debugging and performance tuning.
XPVM provides point-and-click access to the PVM console commands. A pull-down menu allows users to add or delete hosts to configure the virtual machine. Tasks can be spawned using a dialog box that prompts for all spawn options, including the trace mask to determine which PVM routines to trace for XPVM. Spawned tasks automatically send back trace events that describe any desired PVM activity.
The Active color implies that at least one task on that host is busy executing useful work. The System color means that no tasks are busy executing user computation, but that at least one task is busy executing PVM system routines. When there are no tasks on a given hosts, its icon is left uncolored, or white.

The Space-Time View shows the status of individual tasks as they execute across all hosts. The Computing color shows those times when the task is busy executing useful user computations. The Overhead color marks the places where the task executes PVM system routines for communication, task control, etc. The Waiting color indicates those time periods spent waiting for messages from other tasks, i.e. the idle time due to synchronization.

The client machines are usually single-user PCs or workstations that provide a highly user friendly interface to the end user. Each server provides a set of shared user services to the clients. The most common type of server is the database server, usually controlling a relational database. This allows many clients shared access to the same database and the use of a high-performance computer system to manage the database.
A number of characteristics:

The actual functions performed by the application are split up between client and server to optimize:
An essential factor in the success is the way in which the user interacts with the system as a whole. The presentation services should provide a graphical user interface that is easy to use, easy to learn, yet powerful and flexible.
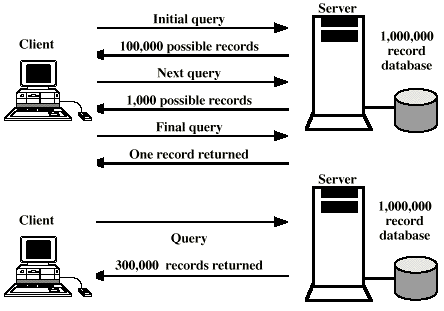
It is not sufficient for the server to only retrieve records for the client, it must also do searches for the client. The number of records transported over the network must be reasonable low.
The client might want to find the grand total or mean value of a number in some field across a large number of records. The server can be equipped with application logic for performing data analyses, to reduce the network traffic. In case the provided functions are not sufficient for a particular user, he or she should be able to do it on the client.

For the calling program on the client this looks like a normal function, e.g. int func(float). But instead of a local function a dummy or stub function is called, with passes information to a similar stub function on the server machine. There the function func() is called, and its return value is transported back to the calling program on the client.
Similar approaches are now also available for object oriented languages and systems.
One of the first available commercial examples. It is used in the Network File System (NFS) allowing workstations to easily use file systems on other workstantions or servers. This consists of the following parts:
The RPC protocol can be implemented on any transport protocol. In the case of TCP/IP, it can use either TCP or UDP as the transport vehicle. In case UDP is used, remember that this does not provide reliability, so it will be up to the caller program itself to ensure this (using timeouts and retransmissions, usually implemented in RPC library routines). Note that even with TCP, the caller program still needs a timeout routine to deal with exceptional situations such as a server crash.
The RPC call message consists of several fields:
As stated above, the caller has to know the exact port number used by a specific RPC program to be able to send a call message to it. Portmap is a server application that will map a program number and its version number to the internet port number used by the program. Because Portmap is assigned a reserved (well-known service) port number 111, all the caller has to do is ask the Portmap service on the remote host about the port used by the desired program. Portmap only knows about RPC programs on the host it runs on (only RPC programs on the local host). In order for Portmap to know about the RPC program, every server RPC program should register itself with the local Portmap when it starts up. It should also cancel its registration when it closes down.
Normally, the calling application would contact Portmap on the destination host to obtain the correct port number for a particular remote program, and then send the call message to this particular port. A variation exists when the caller also sends the procedure data along to Portmap and then the remote Portmap directly invokes the procedure.
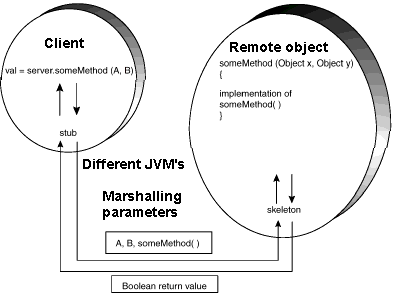
RMI (Remote Method Invocation) is a Java feature similar to RPC. Objects are remote if they reside in a different JVM (Java Virtual Machine), this can be on the same CPU or on another CPU.
If the marshalled parameters are local objects, they are passed by copy using object serialization. These objects must implement the java.io.Serializable interface. Remote objects are passed by reference.
Remote objects are defined by first declaring the interface that specifies the methods that may be invoked remotely. This interface must extend java.rmi.Remote, and each method must throw java.rmi.RemoteException.
The implementation class must extend java.rmi.server.UnicastRemoteObject, allowing the creation of a single remote object that listens for network requests using RMI's default scheme of sockets for network communication. The main() method of the implementation installs a special security manager, creates an instance of the object and registers it with the RMI registry running on the server.
A client can get a reference to a remote object using the Naming.lookup(name) method, where the name is URL like: rmi://host/objectName.
The stub and skeleton class files are generated using the rmic compiler.

CORBA allows heterogeneous client and server applications to communicate, e.g. a C++ program accessing a database written in COBOL. The stubs and skeletons are generated by the Interface Definition Language compiler. CORBA is developed by the Object Management Group, an association of many companies
Microsoft has its own standard Common Object Model (COM), the basis for Object Linking and Embedding (OLE).
Suppose a customer has a bank account distributed over two branches of a bank. Suppose one wishes to calculate the total amount at exactly 3:00. In various ways this can go wrong: an amount may be in transit or the clocks at the two branches are not perfectly synchronized.

The first can be solved by examining all messages in transit at the time of the observation. The state of a branch consists then both of the current balance and the messages that have been sent or received. By examining the states one notice a message that has been sent but not received, its amount must thus be added.
In the second case we see a message that is received, but it is not yet send. The three snapshots are then said to be in an inconsistent state. One of them is running too far behind in time.

Some definitions. A Channel exists between two processes if they exchange messages, for convenience they are viewed as one way. The State of a process includes the sequence of messages that have been sent and received along channels incident with the process, along with possible internal conditions of the process. A Snapshot records the state of a process, each snapshot includes a record of all messages sent and received since the last snapshot. A Distributed snapshot is a collection of snapshots, one for each process. A Global State is the combined state of all processes.
A true global state cannot be determined because of the time lapse associated with message transfers and the difficulty in synchronizing the clocks. One can attempt to define a global state by collecting snapshots from all processes.
An inconsistent global state arises if a process has recorded the receive of a message, but the corresponding sending process has not recorded that the message has been sent.
Distributed snapshot algorithm
Chandy and Lamport (1985) have described an algorithm to record a consistent global state. They assume that messages are delivered in the order they are send and that no messages are lost. This could be achieved e.g. by imposing a message structure on top of TCP. The method uses a special control message, called a marker.
Some process initiates the algorithm by recording its state and sending a marker on all outgoing channels. Upon the first receipt of a marker from process q, process p does:
The 3 actions must be performed atomically, no messages are sent or received in between. At any time later, when p receives a marker from another channel, say r, it records the state of the channel from r to p as the sequence of messages p has received from r from the time p has recorded its local state Sp to the time it received the marker from r. The algorithm terminates at a process once a marker has been received along every incoming channel.
It can be proved that the snapshots present at each process record a consistent global state. To be used the distributed snapshots must be gathered at one or more places.
It can be used to adapt any centralized algorithm to a distributed environment, because the basis of any centralized algorithm is knowledge of the global state.

The model used for examining approaches to mutual exclusion in a distributed context. A number of systems or nodes is assumed interconnected by some network. In each node one process is responsible for resource allocation. It controls a number of resources and services a number of local processes.
Algorithms for mutual exclusion may be centralized or distributed.
In a centralized algorithm one node is designated as the control node, it controls the access to all resources shared over the network. When any process requires access to a critical resource, it issues a request to its local resource controlling process. This process sends this request to the resource controlling process on the control node, which returns a permission message when the shared resource becomes available. When a process has finished with a resource, a release message is sent to the control node. Such a centralized algorithm has two key properties:
It is easy to see how mutual exclusion is enforced. There are however drawbacks. If the central node fails, then the mutual exclusion mechanism breaks down, at least temporarily. Furthermore, every resource allocation and deallocation requires n exchange of messages with the control node and execution time on it. Thus the control node may become a bottleneck.
Because of these problems, there has been much interest in the development of distributed algorithms. A fully distributed algorithm is characterized by the following properties:
With respect to point 2, some distributed algorithms require that all information known to any node be communicated to all other nodes. Even in this case, some of that information is in transit and will not have arrived at all of the other nodes. Thus a node's information is usually not completely up to date, due to time delays in message passing. In that sense it is partial.
With respect to point 6, because of the communication delay, it is impossible to maintain a systemwide clock that is instantly available to all systems. It is also technically impractical to maintain one central clock and to keep all local clocks synchronized precisely to that central clock.
We would like to be able to say that event a at system i occurred before (or after) event b at system j, and to arrive consistently at this conclusion at all nodes. Lamport (1978) has proposed a method, called timestamping which orders events in a distributed system without using physical clocks. This technique is so efficient and effective that it is used in many algorithms for mutual exclusion and deadlock. Ultimately, we are concerned with actions that occur at a local system, such as a process entering or leaving its critical session. However, in a distributed system, processes interact by means of messages. Therefore, it makes sense to associate events with messages, remark that a local event can be bound to a message very simply. To avoid ambiguity, we associate events with the sending of messages only, not with the receipt of messages.

Each node i in the network maintains a local counter Ci, which functions as a clock.
Each time a system transmits a message, it first increments its clock by 1. The message is sent in the
form:
(contents, Ti=Ci, i)
When a message is received, the receiving node j sets its clock as:
Cj := 1 + max( Cj, Ti)
At each node the ordering is then: message x from i precedes message y from j if one of the
following conditions holds:
Ti < Tj
Ti = Tj and i < j
Each message is sent from one process to all other processes. If some are not sent this way, it is impossible that all sites have the same ordering of messages. Only a collection of partial orderings exists.

In the above example P1 begins with its clock at 0. It increments its clock by 1 and transmits (a,1,1), the first 1 is the timestamp and the second the identity of P1. P2 and P3 on receive of the message set their clocks to 1 + max( 1,0) = 2. P2 increments its clock by 1 and transmits (x, 3, 2). At the end, each process agrees to the order {a, x, b ,j}. Note that b might have been send after j in physical time.
The example on the left shows that the algorithm works in spite of differences in transmission time between pair of systems. The message from P1 arrives earlier than that of P4 at site 2 but later at site 3. Nevertheless, after all messages have been received, the ordering is the same at all sites, namely {a, q}.
One of the earliest proposed approaches to providing distributed mutual exclusion is based on
the concept of a distributed queue (Lamport 1978). It uses the previously described model, and assumes
a fully connected network, every process can send a message directly to every other process.
For simplicity, we describe the case in which each site only controls a single resource.
The generalization to multiple resources is trivial.
At each site, a data structure is maintained that keeps a record of the most recent message
received from each site, and the most recent message sent at this site. Lamport refers to this
structure as a queue, actually it is an array with one entry for each site. At any instant,
entry qi[j] in the local array contains a message from Pj. The array is initialized as:
qi[j] = (Release, 0, j) for j = 1, ...., N
Three types of messages are used in this algorithm:
The algorithm is as follows:
It can be shown that this algorithm enforce mutual exclusion, is fair, avoids deadlock and starvation:
Note that 3(N-1) messages are required for each mutual exclusion access. If broadcast is also used this reduces to N+1 messages.
Ricard and Agrawala (1981) optimized the Lamport method by eliminating release messages:
With this method 2(N-1) messages are required, when broadcast is used this becomes N messages.
There are many proposals to achieve mutual exclusion by passing a token among the nodes. One of the most efficient ones was first proposed by Suzuki and Kasami (1982). The token is an array token[k], which records the timestamp of the last time that Pk was visited. In addition each P maintains qi[j], recording the timestamp of the last request received from Pj.
Initially the token is assigned arbitrarily to one of the processes. When a process wishes to enter its critical session, it may do so if it possesses the token. Otherwise it broadcast a timestamped request message and waits until it receives the token. When Pj leaves it critical session, it must transmit the token. It searches qj[] in the order j+1, j+2, ..., 1, ..., j-1 for the first entry k with qj[k] > token[k].
This takes N messages (2 if broadcast is used), when the requesting process does not hold the token, otherwise none.
Gewijzigd op 4 april 2003 door Theo Schouten.