
Race condities en kritieke secties
Een typische situatie waar Dijkstra mee te maken had was er een met twee processen, P1 en P2, die beiden een gedeelde variabele x met 1 verhogen:
| P1: x = x+1 | P2: x = x+1 |
Wanneer x aan het begin de waarde 0 heeft dan zou je verwachten dat na afloop, wanneer P1 en P2 klaar zijn, x de waarde 2 heeft gekregen. Dit is echter niet altijd het geval en dat komt omdat op het laagste niveau de instructie x = x+1 niet atomair is: de instructie x = x+1 wordt vertaald naar een serie machineinstructies waarbij proces P1 eerst de waarde van de gedeelde variabele x copieert naar een lokale variabele l1, dan l1 met 1 ophoogt, en tot slot de waarde van l1 terugschrijft naar x. Bij proces P2 gaat het net zo, alleen wordt dan gebruik gemaakt van een andere lokale variabele l2. Hierdoor is het mogelijk dat eerst P1 de waarde van x copieert naar l1, dat dan P2 de waarde van x copieert naar l2, waarna P1 de waarde van l1 met 1 ophoogt en terugschrijft naar x, waarna P2 de waarde van l2 met 1 ophoogt en terugschrijft naar x. Bij deze volgorde van de machineinstructies zal x na afloop van P1 en P2 de waarde 1 hebben.
Dit is een voorbeeld van een zogenaamde race conditie: een situatie waarin meerdere processen een gedeelde variabele lezen en schrijven, en het uiteindelijke resultaat afhangt van de relatieve snelheid van hun executies. Race condities zijn slecht: we willen niet dat het resultaat van berekening afhangt van toevallige omstandigheden. Race condities zijn de bron van talloze software bugs en vaak erg moeilijk om te vinden: typisch heb je te maken met software die vrijwel altijd goed werkt, maar af en toe opeens een fout antwoord geeft.
Om race condities te voorkomen stelde Dijkstra de notie van een kritieke sectie voor. Een programmeur kan stukken code markeren als kritieke sectie. We eisen vervolgens dat op ieder moment maximaal één proces in zijn kritieke sectie mag zijn. Op deze manier bereiken we wederzijdse uitsluiting of (in het Engels) mutual exclusion. Altijd wanneer er iets is waar slechts één proces tegelijk toegang toe mag hebben (een gedeelde variabele, een printer, netwerktoegang,..) dan kun je dat beschermen met een kritieke sectie. In het voorbeeld van de processen P1 en P2 zou de aangepaste code er alsvolgt uit kunnen zien:
| P1: enter_critical_section() | P2: enter_critical_section() |
| x = x+1 | x = x+1 |
| leave_critical_section() | leave_critical_section() |
Door kritieke secties te gebruiken hebben we de race conditie in dit programma verwijderd: onafhankelijk van de volgorde waarin P1 en P2 worden uitgevoerd zal na afloop de waarde van x altijd 2 hoger zijn dan aan het begin. De vraag is natuurlijk wel hoe we mutual exclusion kunnen realiseren: hoe ziet de code voor enter_critical_section() en leave_critical_section() er uit? Het antwoord op deze vraag is een gedistribueerd algoritme waar alle processen aan mee doen en dat er voor zorgt dat op ieder moment maximaal één van de processen de kritieke sectie in kan.
Vier fundamentele problemen
Bij het realiseren van kritieke secties lopen we tegen vier fundamentele problemen aan, waar we altijd op bedacht moet zijn bij het ontwerpen van gedistribueerde algoritmen:
- Deadlock ("dodelijke omhelzing"): Een situatie waarin twee of meer processen niet verder kunnen omdat elk proces wacht totdat een van de anderen iets heeft gedaan. Een deadlock treedt bijvoorbeeld op wanneer iemand uit Italië in Nederland wil gaan wonen en werken: de gemeenteambtenaar wil de Italiaan pas inschrijven in de gemeente wanneer hij een Nederlandse bankrekening heeft, terwijl de bankmedewerker pas een bankrekening wil openen wanneer de Italiaan staat ingeschreven bij een Nederlandse gemeente.
- Livelock: Een situatie waarin twee of meer processen voortdurend instructies uitvoeren maar er geen vooruitgang wordt geboekt. Een livelock kan bijvoorbeeld optreden wanneer twee mensen elkaar tegenkomen in een nauwe gang en tegenoverelkaar staan: de een doet een stap naar rechts en de ander een stap naar links waardoor ze weer tegenover elkaar staan, dan doet de ene een stap naar links en de ander een stap naar rechts waardoor ze weer tegenover elkaar staan, enzovoorts.
- Starvation ("uithongering"): Een situatie waarin een proces nooit aan de beurt komt omdat het steeds weer op andere processen moet wachten. Starvation kan bijvoorbeeld optreden op een rotonde waar een eindeloze stroom fietsers er voor zorgt dat een automobilist moet wachten tot hij een ons weegt voordat hij de rotonde kan oversteken.
- Busy waiting: Een situatie waarin een proces tijdens het wachten voortdurend (veel en onnodig) processortijd gebruikt. Denk aan je zusje die de hele tijd op de deur staat te bonzen en vraagt wanneer zij nu eindelijk de badkamer in mag.
Software oplossingen voor mutual exclusion
Hieronder bespreken we een aantal "oplossingen" voor het mutual exclusion probleem en illustreren daarmee de problemen van deadlock, livelock, starvation en busy waiting. Voor de eenvoud beperken we ons tot een situatie waarbij er slechts twee processen zijn die toegang willen tot een kritieke sectie. Uiteindelijk gaat mutual exclusion over computerprogramma's die toegang willen tot gedeelde hulpbronnen zoals variabelen en printers, maar je kunt de oplossingen ook gebruiken om afspraken te maken met je zus over wie er wanneer de badkamer in mag!Poging 1
De eerste "oplossing" maakt gebruik van een gedeelde globale variabele turn die de waarden 0 en 1 kan aannemen. (Denk aan een bordje bij de ingang van de badkamer waar met krijt een 0 of een 1 op staat.) Bij aanvang geven we turn de waarde 0. Het idee is dat variabele turn aangeeft wie er de beurt heeft. Wanneer een proces de kritieke sectie in wil wacht het steeds net zo lang tot het de beurt heeft. Bij het verlaten van de kritieke sectie geeft een proces de beurt aan het andere proces.| Proces 0 | Proces 1 |
| ... | ... |
| while turn != 0 | while turn != 1 |
| do { niets }; | do { niets }; |
| "kritieke sectie" ; | "kritieke sectie"; |
| turn = 1 | turn = 0 |
| ... | ... |
Bovenstaande code garandeert mutual exclusion maar heeft serieuze nadelen. Allereerst is er natuurlijk sprake van busy waiting. Maar ernstiger is dat de processen om en om de kritieke sectie moeten binnengaan. Wanneer het ene proces elk uur de kritieke sectie in wil terwijl het andere proces dit slechts eens per dag doet, dan zal het eerste proces enorm vertraagd worden. In het meest extreme geval, wanneer een van de processen geen toegang meer vraagt tot de kritieke sectie en een ander proces wel, kan er starvation optreden.
Poging 2
De tweede "oplossing" maakt gebruik van twee gedeelde Boolese variabelen flag[0] en flag[1], die in het begin allebei false zijn. De intuitie hierbij is dat ieder proces een vlag heeft, die aanvankelijk is gestreken. Wanneer een proces de kritieke sectie in wil wacht het eerst net zo lang totdat de vlag van het andere proces niet meer is opgehesen. Zodra dit het geval is hijst het proces zijn eigen vlag op en gaat de kritieke sectie in. Bij het verlaten van de kritieke sectie strijkt een proces zijn vlag..| Proces 0 | Proces 1 |
| ... | ... |
| while flag[1] | while flag[0] |
| do { niets }; | do { niets }; |
| flag[0] = true; | flag[1] = true ; |
| "kritieke sectie"; | "kritieke sectie"; |
| flag[0] = false; | flag[1] = false; |
| ... | ... |
Deze "oplossing" is natuurlijk helemaal fout. Het probleem doet zich voor wanneer eerst Proces 0 de eerste regel uitvoert en gelijk daarna Proces 1. Beide processen zien dat de vlag van de andere
gestreken is, hijsen vervolgens hun eigen vlag en gaan vrolijk de kritieke sectie binnen. Er is dus niet voldaan aan mutual exclusion.
Poging 3
De derde "oplossing" maakt ook gebruik van twee vlaggen maar doet dit voorzichtiger: voordat een proces kijkt naar de vlag van de ander hijst het nu eerst de eigen vlag.| Proces 0 | Proces 1 |
| ... | ... |
| flag[0] = true; | flag[1] = true; |
| while flag[1] | while flag[0] |
| do {niets }; | do {niets }; |
| "kritieke sectie"; | "kritieke sectie"; |
| flag[0] = false; | flag[1] = false; |
| ... | ... |
Maar ook deze "oplossing" is fout: wanneer eerst Proces 0 zijn vlag hijst en direct daarna hijst ook Proces 1 zijn vlag, dan komt geen van beide processen ooit nog de kritieke sectie in. De processen zijn "te beleefd" en er is sprake van een deadlock..
Poging 4
De vierde "oplossing" is een variant van de derde "oplossing" waarbij een proces de vlag weer strijkt op het moment dat er een deadlock dreigt:| Proces 0 | Proces 1 |
| ... | ... |
| flag[0] = true; | flag[1] = true; |
| while flag[1] do | while flag[0] do |
| { flag[0] = false; | { flag[1] = false; |
| "wacht even"; | "wacht even" |
| flag[0] = true; }; | flag[1] = true; }; |
| "kritieke sectie"; | "kritieke sectie"; |
| flag[0] = false; | flag[1] = false; |
| ... | ... |
We zitten nu dicht bij een oplossing, maar het kan nog steeds misgaan. Wanneer Proces 0 en Proces 1 om en om een regel code uitvoeren zullen ze tot in het oneindige vlaggen blijven hijsen en strijken maar zal nooit iemand de kritieke sectie binnenkomen: de code laat een livelock scenario toe.
Oplossing
De Nederlandse wiskundige Dekker bedacht in 1965 de eerste een correcte oplossing voor het mutual exclusion algoritme. Zijn oplossing maakt zowel gebruik van gedeelde variabelen flag[0] en flag[1] als van een variabele turn. Dekker gebruikte de variabele turn om een knoop door te hakken indien beide processen tegelijk de kritieke sectie in willen. De oplossing van Dekker was nogal complex, maar gebruikmakend van hetzelfde idee kwam Peterson in 1981 met de simpele en elegante oplossing die hieronder staat.| Proces 0 | Proces 1 |
| ... | ... |
| flag[0] = true; | flag[1] = true; |
| turn = 1; | turn = 0; |
| while (flag[1] && turn = 1) | while (flag[0] && turn = 0) |
| do { niets }; | do { niets }; |
| "kritieke sectie"; | "kritieke sectie"; |
| flag[0] = false; | flag[1] = false; |
| ... | ... |
Het enige bezwaar dat nog aan deze oplossing kleeft is dat er sprake is van busy waiting.
Uppaal
Hoe weten we eigenlijk zo zeker dat de oplossing van Peterson correct is? Immers, alle andere "oplossingen" bleken ook fout te zijn. Hoe kunnen we uitsluiten dat dit ook niet het geval is bij Peterson's oplossing? Hieronder presenteren we een Uppaal model van Peterson's algoritme. Door dit model te analyseren met Uppaal kunnen we bewijzen dat er voldaan is aan de gewenste eigenschappen. Het model bestaat uit twee instanties van een template P: twee processen die in parallel draaien: eentje met pid ("process identifier") waarde 0 en eentje met pid waarde 1.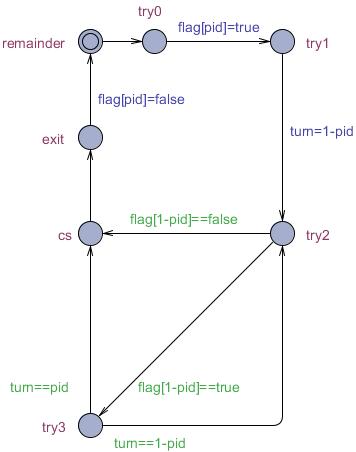
De vertaling van pseudocode naar Uppaal is recht-toe-recht-aan. Om tot uitdrukking te brengen dat een proces meerdere keren de kritieke sectie in kan, keert de automaat na het verlaten van de kritieke sectie weer terug naar de startlocatie. De startlocatie beschrijft de toestand waarin het proces met andere zaken bezig is en niet de kritieke sectie in wil. Zodra een proces de kritieke sectie in wil springt het naar locatie try0. Een belangrijk aspect van Peterson's algoritme is dat de conditie flag[1-pid] && turn == 1-pid niet atomair is. Het kan bijvoorbeeld gebeuren dat proces P(0) eerst flag[1] evalueert, dat vervolgens proces P(1) een aantal stappen doet, en dat pas daarna het tweede deel van de conditie turn == 1 wordt geëvalueerd. In het model wordt de evaluatie van de conditie daarom ook beschreven met twee opeenvolgende transities: wanneer in locatie try2 variabele flag[1-pid] op false staat kan de conditie flag[1-pid] && turn == 1-pid niet tot true evalueren en mag het proces de kritieke sectie in. Indien daarentegen flag[1-pid] op true staat dan moet het tweede deel van de conditie ook nog bekeken worden. Dit gebeurt in locatie try3: als turn==pid mag het proces de kritieke sectie in, anders gaat het terug naar try2.
Met behulp van Uppaal kunnen we eenvoudig laten zien dat Peterson's algoritme voldoet aan mutual exclusion: voor alle bereikbare toestanden geldt dat P(0) en P(1) niet tegelijkertijd in de kritieke sectie kunnen zijn:
Er is dus voldaan aan de mutual exclusion eis. Ook kunnen we met Uppaal laten zien dat het algoritme geen deadlocks heeft: er is altijd een transitie mogelijk. In een van de opdrachten zullen we het model van Peterson's algoritme nog verder bestuderen.
A[] ( not( P(0).cs and P(1).cs ))