A3 H6 The Transport Layer
Its task is to provide reliable, cost-effective data transport
from the source machine to the destination machine, independent of
the physical network or networks currently in use.
6.1 The transport service
6.1.1 Services provided to the upper layers
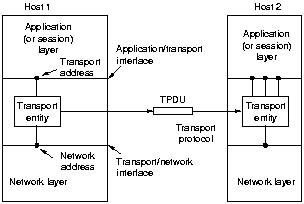
The transport entity can be in the operating system kernel, in
a separate user process, in a library package bound into network
applications, or on a network interface card. There are 2 types of
transport services, connection-oriented and connectionless, just
as in the network layer, and they are very similar to them. Why
are there than 2 separate layers?. The answer is subtle, but
crucial. The network layer is part of the communication subnet and
is run by the carrier, at least for the WAN. The users have no
control over this, what happens if the offered connection-oriented
service is unreliable, frequently loses packets or its routers
crash from time to time? The user can not put in better routers or
put more error handling in the data link layer.
In essence, the transport layer makes it possible for the transport service to be
more reliable than the underlying network service, lost packets
and mangled data can be detected and compensated for. Furthermore,
the transport service primitives can be designed to be independent
of the network service primitives, which may vary considerably
from network to network (e.g. a connectionless LAN service may be
quite different than a connection-oriented WAN service)
Due to the transport layer, application programs can be
written using a standard set of primitives so that they can work on a
wide variety of networks without having to worry about dealing with
different subnet interfaces and unreliable transmissions. The bottom
4 layers are therefore sometimes seen as the transport service
provider and the higher layers as the transport service user.
6.1.2 Transport service primitives
| Primitive |
TPDU sent |
Meaning |
| Listen | none | Block until some process tries to connect |
| Connect | Connection request | Actively attempt to establish a connection |
| Send | Data | Send information |
| Receive | none | Block until a Data TPDU arrives |
| Disconnect | Disconnection req. | This side wants to release the connection |
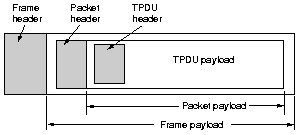
The primitives for a simple transport service. TPDU means
Transport Protocol Data Unit. To the transport users, a
connection is a reliable bit pipe: one user stuffs bits in and
they magically appear at the other end.
Disconnection, meaning
no more data needs to be send and the used buffer space can be
released, has 2 variants. In the asymmetric variant, either transport user can issue a
disconnect primitive, which results in a disconnect TPDU being
sent to the remote transport entity. Upon arrival the connection
is released. In the symmetric variant, each direction is closed
separately, independent of the other one. When one side does a
disconnect, it means it has no more data to send, but is still
willing to accept data from its partner. A connection is released
when both sides have done a disconnect.

A state diagram for connection establishment and release for these
simple primitives. Each transition is triggered by some event,
either a primitive executed by the local transport user or an
incoming packet (labeled in italics).
The solid lines show the client's state sequence, the dashed lines the server ones.
6.1.3 Berkeley sockets
| Primitive | Meaning |
| SOCKET |
Create a new communication end point. The parameters specify
the addressing format, the type of service (e.g. reliable byte
stream) and the protocol. It returns an ordinary file descriptor
for use in succeeding calls, the same way as an OPEN call does. |
| BIND | Binds a local address to a socket. |
| LISTEN |
Allocates space to queue incoming calls for the case that
several clients try to connect at the same time, it does not
block. |
| ACCEPT |
Blocks a server until a connect request TPDU from a client
arrives. A new socket with the same properties as the original
LISTEN one is then created by the transport entity and a file
descriptor for it is returned. The server can then fork off a
process or tread to handle the connection on the new socket
and go back to waiting for the next connection on the original
socket by issuing a new ACCEPT primitive. |
| CONNECT |
Issued by a client after it has created a socket, it blocks the
client and actively starts the connection process. When it
completes (the appropriate TPDU is received from the server),
the client process is unblocked and the connection is established. |
| SEND | Sends some data over the connection. |
| RECEIVE | Receives some data from the connection |
| CLOSE | Symmetric connection release. |
6.2 Elements of transport protocols
In some ways, transport protocols resemble the data link protocols,
both have to deal with error control, sequencing, flow control and
other issues.
In the transport layer explicit addressing of
destinations is needed.
The potential existence of storage
capacity in the subnet has to be dealt with. If the subnet uses
datagrams and adaptive routing inside, there is the possibility
that a packet might be stored for a number of seconds and then
delivered later. This can sometimes be disastrous, specially
during connection and disconnection, and requires the use of special protocols.
Buffering and flow control are needed in both layers, but the
presence of a large and dynamically varying number of connections
in the transport layer, may require a different approach than is
used in the data link layer. The idea of dedicating many buffers
to each connection in the transport layer is not attractive.
6.2.1 Addressing
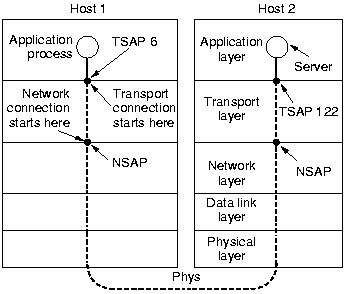 |
Transport layer addresses are called TSAP (Transport Service Access
Point). In Internet, they consists of an (IP address, local port)
pair, in ATM of an (AAL, SAP) pair. An IP address is an example of
a NSAP.
How does the user process on host 1 know that the address of
the server, e.g. the time-of-day server, is attached to TSAP 122?
One possibility is, that it has always been there and every one
knows it. This might work for a small number of key services that
never change, but, in general, user processes often want to talk
to other user processes that only exist for a short time and do
not have a TSAP that is known in advance. Furthermore, if there
are potentially many server processes, most of which are rarely
used, it is wasteful to have each of them active and listening to
a stable TSAP all day long.
|
In the initial connection protocol, used by UNIX hosts,
each machine that wishes to offer services to remote users, has a
special process server, that acts as a proxy for
less-heavily used servers. It listens to a set of ports at the
same time, waiting for a TCP connection request. If a request
comes in, the process server spawns off the requested server,
allowing it to inherit the existing connection with the user. The
new server does the work and the process server goes back
listening for new requests.
Often a name server or directory server is used.
It listens at a well know port for clients which can ask for the TSAP
corresponding with a given service name, e.g. time-of-day. After
receiving the TSAP, the client disconnects and establishes a
connection with the service of which it now knows the TSAP. When a
new service is created, it must register itself with the name server,
giving it its name (typically an ASCII string) and the address of its TSAP.
6.2.2 Establishing a connection
The problem here is the existence of delayed duplicates. It can be
attacked in various ways, none of them very satisfactory.
One way is to use throwaway transport addresses, each time a
transport address is needed, a new one is generated. This makes the
process server model impossible. Another way is to give each
connection a connection identifier (e.g. a sequence number
incremented for each connection established), chosen by the
initiating party, and put that in each TPDU. After a connection is
released, each transport entity could update a table listing obsolete
connections as (peer transport entity, connection identifier) pairs.
Whenever a connection request came in, it could be checked against
the table. This scheme has a basic flow: it requires each transport
entity to maintain a certain amount of history information
indefinitely and that could be lost when the machine crashes.
If we can assure that no packet lives longer than some known time,
the problem become somewhat more manageable. This can be achieved
using one of the following techniques: restricting subnet design,
using a hop or time-to-live field in each packet, or timestamping
each packet (times must somehow be synchronized between hosts). In
practice, we will need to guarantee not only that a packet is dead,
but also that all acks to it are dead, so we will now introduce T,
some small multiple of the true maximum lifetime of a packet (and its
acks).
With packet lifetimes bounded, it is possible to devise a
foolproof way to establish connections. Each host is equipped with a
time-of-day clock, a binary counter that increments itself at uniform
intervals. The number of bits must equal or exceed the number of bits
in the sequence numbers used in the TPDU's. The clock is assumed to
continue running even if the host goes down. The clocks at different
hosts need not to be synchronized. The basic idea is that two
identical numbered TPDU's are never outstanding at the same time. When
a connection is set up, the low-order k bits of the clock are used as
the initial sequence number (also k bits). The sequence space should
be so large that by the time sequence numbers wrap around, old TPDU's
with the same sequence number are long gone.
When a host comes up after a crash, its transport entity does not
know were it was in the sequence space. One solution is to let the
transport entity wait for T sec after it comes up, but this might be
too long in a complex internetwork.
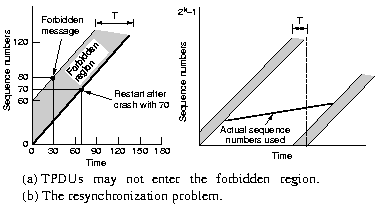 |
Another way is to prevent seqs from being used for a time T before their
potential use as initial sequence numbers. The forbidden region
can be entered in two ways.
From underneath if data TPDU's are
send to fast. Thus the maximum rate per connection should be 1
TPDU per clock tick. The clock tick should thus be short.
From
the left is also possible, this should be checked and either the
TPDU should be delayed for T sec or the sequence numbers should be resynchronized.
|
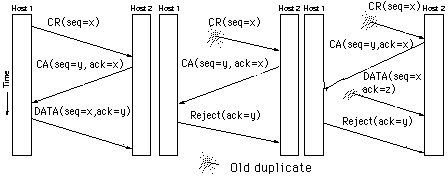
| For connection a three-way handshake is used. When a host send
a sequence number with a CR (connection request) or a CA
(connection accept) it assures that no TPDU's or acks with that
sequence number can be in existence.
The important thing is that no combination of old CA, CR or
other TPDU can cause a connection to be set up by accident.
|
6.2.3 Releasing a connection
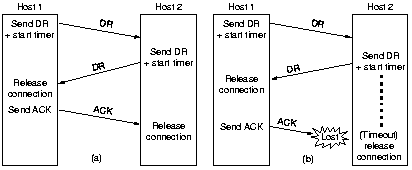 |
Asymmetric release is abrupt and may result in data loss, in case one site
sends a disconnect request while data from the other side is still
under way. Therefore usually symmetric release is used.
A three-way handshake is usually used to release a connection.
Timers must be used to handle the cases that TPDU's are lost.
|
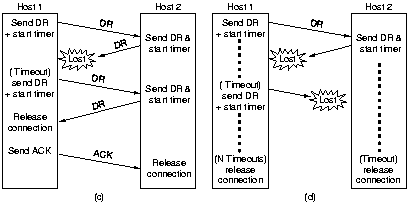 |
In order to handle the case that a lot of TPDU's are lost the number
of retransmissions can be maximized.
Another way of assuring termination is to have a rule saying
that a connection is automatically terminated if no TPDU is
received for a certain number of seconds. It is then necessary for
each transport entity to have a timer that is restarted after each
TPDU sent. If this timer expires, a dummy TPDU must be sent, just
to keep the other side from disconnecting.
|
6.2.4 Flow control
The basic similarity between data link and transport layer flow
control is that in both layers a sliding window or other scheme is
needed on each connection to keep a fast transmitter from overrunning
a slow receiver. The main difference is that a router has relatively
few lines whereas a host may have numerous open connections.
If the network service is unreliable, the sender must buffer all
TPDU's sent, just as in the data link layer. With reliable network
services, other tradeoffs become possible. If the sender knows that
the receiver always has buffer space, it need not to retain TPDU's it
sends. Otherwise it will have to buffer anyway, because the network
layer acknowledgment only means that the TPDU has arrived, not that
it was accepted.
The optimum tradeoff between source and destination buffering
depends on the type of traffic. For low bandwidth, bursty traffic
(like produced by an interactive terminal) it is better to buffer at
the sender, using dynamically acquired buffers. For high bandwidth,
smooth traffic (like a file transfer) it is better to buffer at the
receiver, to allow the data to flow at maximum speed.
As connections are opened and closed and as the traffic pattern
changes, the sender and receiver need to dynamically adjust their
buffer allocations. Depending on the variation in TPDU size, one can
opt for a chained fixed or variable size buffer or a large circular
buffer per connection.
A general way to manage dynamic buffer allocation is to decouple
the buffering from the acknowledgments, in contrast to the sliding
window protocol of the data link layer. Initially the sender requests
a certain amount of buffer space on the receiver side, based on its
perceived needs. The receiver grants as many as it can afford. Every
time the sender transmits a TPDU, it must decrement its allocation,
stopping all together if it reaches 0. The receiver then separately
piggybacks both acks and the amount of available buffer space onto
the reversed traffic. Dynamic buffer management means, in effect, a
variable sized window.
6.2.5 - 6.2.6 Not for this course.
6.3 A simple transport protocol
Not for this course.
6.4 The Internet transport protocol UDP
6.4.1 Introduction to UDP
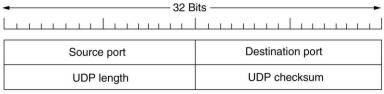
UDP (User Datagram Protocol) is just basically IP with a
short header added. The port numbers indicate the sending and receiving
transport end points. When a UDP packet arrives, its payload is send to the
process attached to the destination port.
The checksum is optional and stored as 0 if not computed, a calculated 0 checksum
is stored as all 1s.
UDP does not do flow control, error control or retransmission upon receipt of a bad segment.
All of that is up to the user processes.
6.4.2 RPC: Remote Procedure Call
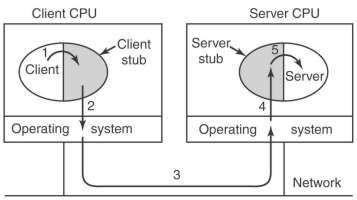
For the calling program on the client this looks like a normal function, e.g. int func(float)
or get_IP_adress(host_name). But instead of
a local function a dummy or stub function is called, with passes information to a similar stub
function on the server machine. There the real function is called, and its return value is transported back
to the calling program on the client.
The packing of parameters into a message is called marshaling.
A problem arises when pointers are used as parameters or if global variables are used. The call-by-reference
can be replaced by copy-restore, but that will not work if the pointer points to a graph or other complex data structure.
RPC can best be used if the function is idempotent, meaning it can be repeated safely. In that case
UDP can be used, the client stub just sends the message again if no answer comes back in time or the received answer segment
has a checksum error.
6.4.3 RTP: Real Time Transport Protocol
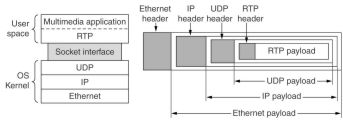
RTP is intended for real-time multimedia applications, like radio, telephony, music-on-demand, videoconferencing,
video-on-command, etc.
Its basic function is to multiplex several real-time data streams into a single stream of UDP packets,
send to a single or to multiple destinations. It may contain for example a video stream and 2 audio stream
for stereo or sound tracks in 2 languages. The packets receive no special treatment from routers
unless some quality-of-service features of the IP packets are enabled.
RTP packets have a sequence number. If a receiver misses one, the best action is probably to approximate
missing values by interpolation, since a retransmission would probably come to late.
Each payload may contain multiple samples, they may be coded any way the uses wants. The payload type field
in the header indicates which one is used.
The time of each sample relative to the first sample in the stream can be indicated in the header by the sender.
The receiver can use this to buffer incoming samples and to use each sample at the right moment, this to reduce jitter effects.
RTCP (Real Time Control Protocol) can be used to handle feedback, synchronization and the user interface.
The feedback can be used to provide information on delay, jitter, bandwidth, congestion and other network properties to the source.
The encoding process can use it increase the data rate and give better quality if the network is functioning well, otherwise
it can cutback in quality and data rate. By providing continuous feedback the best quality under the current
circumstances can be provided.
RTCP provides also for synchronizing multiple data streams, e.g. video and sound.
Further it provides names (e.g. in ASCII text) for the various data streams, to be shown to the user.
6.5 The Internet transport protocol TCP
6.5.1 Introduction to TCP
TCP (Transmission Control Protocol) provides a reliable
byte stream over an unreliable internetwork. Each machine supporting
TCP has a TCP transport entity, either a user process or part of the
kernel, that manages TCP streams (connections) and interfaces to the
IP layer. A TCP entity accepts user data streams from local
processes, breaks them up into pieces not exceeding 64K (usually
about 1460 bytes to fit in a single Ethernet frame) and sends each piece as a separate IP datagram. The
receiver side gives IP datagrams containing TCP data to its TCP
entity, which reconstructs the original byte streams.
IP gives no guarantees that datagrams will be delivered properly,
so it is up to TCP to time out and retransmit. Also IP datagrams
might be delivered in the wrong order, it is up to TCP to rearrange
them in the proper sequence.
6.5.2 The TCP service model
The TCP service is obtained by having both the sender and receiver
create end points, called sockets. Each socket has a socket
number (address) consisting of the IP address of the host and a 16
bit number local to that host, called a port. A port is the
TCP name for a TSAP. A connection must then explicitly be established
between a socket on the sending machine and a socket on the receiving
machine. Two or more connections may terminate at the same socket.
Connections are identified by the socket identifiers at both ends,
that is (socket1, socket2). No VC numbers or other identifiers are
used. Port numbers below 1024 are called well-known ports and
are reserved for standard services, like FTP or TELNET.
All TCP connections are full-duplex (traffic can go in both
directions) and point-to-point (each connection has exactly 2 end
points). Multicasting or broadcasting are not supported. A TCP
connection is a byte stream, not a message stream. For example, if
the sending process does four 512 byte writes to a TCP stream, these
data may be delivered to the receiving process as four 512 byte
chunks, two 1024 bytes chunks, one 2048 byte chunk or some other way.
This is analogous to UNIX files.
TCP may send user data immediately or buffer it, in order to send
larger IP datagrams. Applications might use the PUSH flag to
indicate that TCP should send the data immediately. The application
can also send urgent data (e.g. when an interactive user hits
the CTRL-C key), TCP then puts control information in its header and
the receiving side interrupts (gives a signal in UNIX terms) to the
application program using the connection. The end of the urgent data
is marked, but not its beginning, the receiving application has to
figure that out. This provides a crude signaling mechanism.
6.5.3 The TCP protocol
Every byte on a TCP connection has its own unsigned 32 bit
sequence number. They are used both for acks, which uses a 32 bit header field and for the window
mechanism, which uses a separate 16 bit header field.
The sending and receiving TCP entities exchange data in the form
of segments. A segment consists of a fixed 20 byte header
(plus an optional part) followed by 0 or more data bytes. The TCP
software decides how big segments should be, it can accumulate bytes
from several writes into one segment or split data from one write
over multiple segments. Each segment (including the header) must fit
into the 64K IP payload. Each network has a MTU (maximum
transfer unit) and a segment must fit in it. In practice, the MTU is
generally a few thousand bytes and thus defines the upper bound on
segment size. If a segment passes through a sequence of networks and
hits one whose MTU is smaller than the segment, the router at the
boundary fragments the segment. Each fragment is a new segment having
its own TCP and IP header, thus fragmentation increases the total
overhead.
TCP basically uses a sliding window protocol. On sending a segment
a timer is started, on arrival the receiver sends back a segment
(with data if any exists) bearing an ack equal to the next sequence
number it expects to receive. This sounds simple, but segments can be
fragmented and the parts can be lost or delayed so much that a
retransmission occurs. If a retransmitted segments takes a different
route and is fragmented differently, bytes and pieces of both the
original and the duplicate can arrive sporadically, requiring a
careful administration to achieve a reliable byte stream.
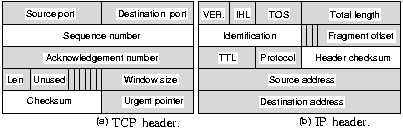
6.5.4 The TCP header
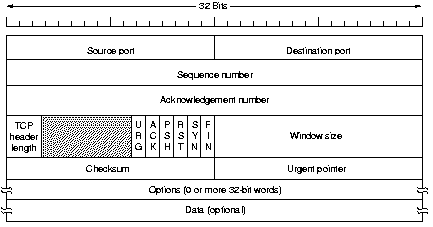
URG is set to 1 if the urgent pointer is in use which indicates a byte
offset from the current sequence number to the end of the urgent
data. An ACK of 1 indicates a valid ack number. The PSH bit
indicates pushed data, requesting the receiver to deliver the
received data directly to its application program and not buffer
it. The RST bit is used to reset a connection that has become
confused due to a host crash or some other reason.
The SYN bit is used to establish a connection and the FIN bit to release one.
The latter tells that the sender has no more data to send, but it
may continue to receive data. Both SYN and FIN segments have
sequence numbers and are thus guaranteed to be processed in the correct order.
The window field tells how many bytes may be
sent starting at the byte acknowledged. A window field of 0 is
valid, it tells the sender to be quiet for a while. Permission to
send can be granted later by sending a segment with the same ack
number and a nonzero window field.
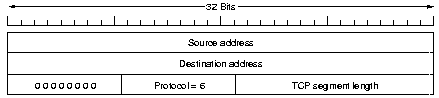
A checksum is also provided for extreme reliability. It checksums
the header, the data and the conceptual pseudo header. The
checksum is a simple one, just adding the 16-bits words (using
padding if needed) in 1's complement and then take the 1's
complement of the sum. The receiving side should thus find a checksum of 0.
The pseudoheader contains IP addresses and thus
violates the protocol hierarchy. It helps to detect misdelivered packets.
The options field was designed to provide a way to add extra
facilities. An important option is to allow each host to specify the
maximum TCP payload it is willing to accept (small host might not be
able to accept very large segments). During connection, each side can
announce its maximum and the smallest is taken. If a host does not
use this option, it defaults to a 536 byte payload, which all
Internet hosts are required to accept.
For lines with high bandwidth, high delay or both, the 64 KByte
window is often a problem. On a T3 line (44.736 Mbps), it takes only
12 msec to output. If the round trip propagation is 50 msec (typical
for a transcontinental fiber), the sender will be idle 75% of the
time waiting for an ack. The window scale options allows both sides
to negotiate a scale factor for the window field, allowing windows of
up to 4 GBytes. Most TCP implementations now support this option.
Another option (proposed in RFC 1106 and widely implemented) is
the use of selective repeat instead of go back n. It introduced NAK's,
to allow the receiver to ask for specific, not (yet) received data
bytes, after it has received following bytes. After it gets these, it
can ack all its buffered data, thus reducing the amount of
retransmitted data. This is nowadays important as memory is cheap and
bandwidth is still small or expensive.
6.5.5 - 6.5.7 TCP connection management
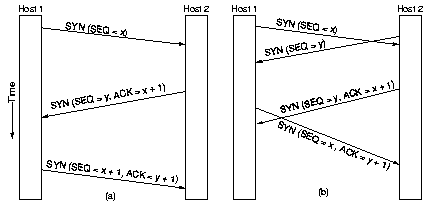
To establish a connection, one side, say the server, passively waits
for an incoming connection by executing the listen and accept
primitives, either specifying a particular other side or nobody in
particular. The other side executes a connect primitive,
specifying the IP and port to which it wants to connect, the
maximum TCP segment size, possible other options and optionally
some user data (e.g. a password). The connect primitive sends a
TCP segment with the SYN bit on and the ACK bit off.
The receiving server checks to see if there is a process that has done a listen
on the port given in the destination field. If not, it sends a
reply with the RST bit on to reject the connection. Otherwise it
gives the TCP segment to the listening process, which can accept
or refuse (e.g. if it does not like the client) the connection. On
acception a SYN is send, otherwise a RST. Note that a SYN segment
occupies 1 byte of sequence space so it can be acked unambiguously.
In the event that 2 host simultaneously attempt
to establish a connection between the same two sockets, still just
one connection is established, because connections are identified by their end points.
For the initial sequence number a clock based scheme is used,
with a clock tick every 4 µsec. For additional safety, when a
host crashes it may not reboot for 120 sec.
| State | Description |
| CLOSED | No connection is active or pending |
| LISTEN | The server is waiting for an incoming call |
| SYN RCVD | A connection request has arrived; wait for ACK |
| SYN SENT | The application has started to open a connection |
| ESTABLISHED | The normal data transfer state |
| FIN WAIT 1 | The application has said it is finished |
| FIN WAIT 2 | The other side has agreed to release |
| TIMED WAIT | Wait for all packets to die off |
| CLOSING | Both sides have tried to close simultaneously |
| CLOSE WAIT | The other side has initiated a release |
| LAST ACK | Wait for ack of FIN of last close |
Releasing a TCP connection is symmetric. Either part can
send a TCP segment with the FIN bit set, meaning it has no more
data to send. When the FIN is acked, that direction is shut down,
but data may continue to flow indefinitely in the other direction.
If a response to a FIN is not received within 2
maximum packet lifetimes, the sender of the FIN releases the
connection. The receiver will eventually notice that it receives
no more data and timeout as well.
There are 11 states used in the TCP connection management
finite state machine. Data can be send in the ESTABLISHED and the
CLOSE WAIT states and received in the ESTABLISHED and FINWAIT1
states.
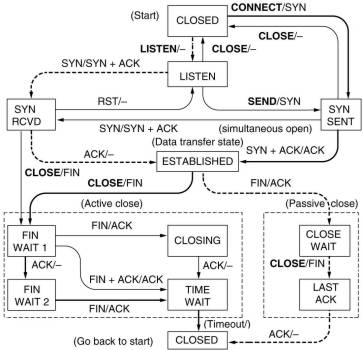 |
TCP connection management final state machine. The heavy solid line is
the normal path for the client, the heavy dashed line that for the server.
Each line is marked by an event/action pair. The event can
either be a user-initiated system call (CONNECT, LISTEN, SEND or
CLOSE), a segment arrival (SYN, FIN, ACK or RST), or a timeout.
For the TIMED WAIT state the event can only be a timeout of twice
the maximum packet length. The action is the sending of a control
segment (SYN, FIN or RST) or nothing.
The time-outs to guard for lost packets ( e.g. in the SYN SENT
state) are not shown here.
|
6.5.8 TCP transmission policy
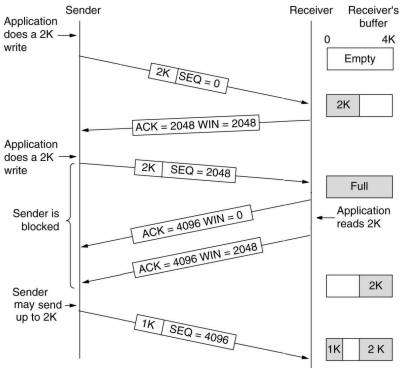
Window management in TCP is decoupled from acks.
When the window is 0,
the sender may not normally send segments, with two exceptions.
First, urgent data may be send, e.g. to allow the user to kill the
process running on the other machine. Second, the sender may send
a 1-byte segment to make the receiver reannounce the next byte
expected and the window size. This is used to prevent deadlock if
a window announcement ever gets lost.
Senders are not required to transmit data as soon as they come
in from the application. Usually Nagle's algorithm is used.
When data come into the sender one byte at a time (e.g. on a
Telnet connection), just the first byte is send and the rest is
buffered until the outstanding byte is acked. Sometimes it is
better to disable this, e.g. when mouse movements are sent in
X-Windows applications.
Receivers are also not required to send
acks and window updates immediately. Many implementations delay
them for 500 msec in the hope of acquiring some data on which to hitch a free ride.
Another problem is the silly window syndrome, occurring
when the sender transmit data in large blocks, but an interactive
application on the receiver side reads data 1 byte at a time. The
receiver continuously gives 1 byte window updates and the sender
transmits 1 byte segments. Clark's solution is to let the receiver
only send updates when it can handle the maximum segment size it
advertised when the connection was established or when its buffer
is half empty.
The receiver usually uses selective update, but go back n can also be used.
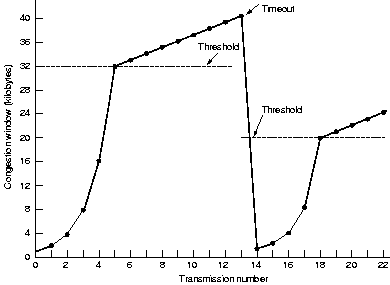
6.5.9 TCP congestion control
All Internet TCP algorithms assume that time-outs are caused by
congestion due to network and receiver capacity as lost packets
due to noise on the transmission lines are rare these days. Each
sender maintains two windows: the window the receiver has granted
(indicating the receiver capacity) and the congestion window
(indicating the network capacity). The number of bytes that may be
sent is the minimum of the 2 windows.
Initially the congestion window is the MTU. It is doubled on
each burst successfully (an ack received before the timeout) sent.
This exponential increase (called the slow start) continues
until the threshold (initially 64K) is reached, after which
the increase is linearly with 1 MTU.
When a timeout occurs, the
threshold is set to half the current congestion window and the
slow start is repeated. If an ICMP source quench packet comes in,
it is treated the same way as a timeout.
6.5.10 TCP timer management

The retransmission timer has to handle the large variation in
round trip time occurring in TCP. See the example right, on the left is a normal
situation for the data link layer. For each segment the round trip
time M is measured and the estimates of the mean and mean
deviation are updated as:
RTT = ßRTT + (1-ß)M
D = ßD + (1-ß) |RTT-M|
with ß a smoothing
parameter, typically 7/8. The timeout is then set to: RTT + 4 D
With Karn's algorithm, RTT and D are not updated for
retransmitted segments. Instead, the timeout is doubled on each
failure until the segments get through the first time.
When a window size of 0 is received, the persistence timer
is used to guard against the lost of the next window update.
Some implementations also use a keepalive timer. When a
connection has been idle for a long time, the timeout causes a packet
to be send to see if the other side is still alive. If it fails to
respond, the connection is terminated. This feature is controversial
because it adds overhead and may terminate an otherwise healthy
connection due to a transient network problem.
The last timer is the one used in the TIMED WAIT state while
closing, running for twice the maximum packet lifetime to make sure
that when a connection is closed, all packets created by it have died
off.
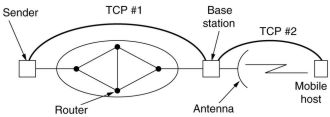
6.5.11 Wireless TCP and UDP
In theory, transport protocols should be independent of the technology of the underlying network layer.
In practice, most TCP implementations have been carefully optimized based on assumptions
that are true for wired networks but not for wireless networks. Off coarse, they work correctly for
wireless network, but the performance is low.
On a wireless network if a packet is lost, it is usually not due to congestion, but due to "noise" on the
transmission. TCP should not slow down, but retransmit as soon as possible.
That can be done on a host which knows it sends over a wireless network, but what if the first part
of a connection from a sender to a receiver is over a wired network, and the last part over a wireless link?
Using an indirect TCP solution is a possibility. But the acknowledgment, returned from the base station
to the sender, does not indicate that the mobile host has received the data. Another possibility is to add
a snooping agent on the base station. It watches the interchange between base station and mobile host
and performs retransmissions (and interception of duplicated acknowledgments) on that part alone.
However there is still the possibility that the sender times out and starts it congestion control.
6.5.12 Transactional TCP
Not for this course.
6.6 Performance issues
When thousands of computers are connected together, complex
interactions with unforeseen consequences, are common. Frequently,
this complexity leads to poor performance and no one knows why.
Unfortunately, understanding network performance is more of an art
than a science. There is little underlying theory that is actually of
any use in practice.
The transport layer is not the only place performance issues
arise. We saw some of them already in the network layer related to
routing and congestion control. However, the broader, system oriented
issues tend to be transport related.
6.6.1 Performance problems in computer networks
Some problems, such as congestion, are caused by temporary
resource overloads. If more traffic suddenly arrives at a router than
the router can handle, congestion will build up and performance will
suffer, as we already studied. When there is a structural resource
imbalance, like a high speed line connected to a low end PC,
performance will also suffer.
Overloads can also be synchronously triggered. For example, if a
TPDU contains a bad parameter, in many cases the receiver will send
back an error notification. Consider a bad TPDU broadcasted to 10000
machines, the resulting broadcast storm of error messages
could cripple the network. UDP suffered from this problem until the
protocol was changed to not sending error messages for bad UDP TPDU's
sent to broadcast addresses. Another example is what happens after an
electrical power failure. When power comes back on, all the machines
start rebooting, which might require going to a (RARP) server to
learn ones' true identity and then to some file server to get a copy
of the operating system. If hundreds of systems all do this at once,
the server might collapse under the load.
Another tuning issue is setting time-outs correctly.
A quantity to keep in mind is the bandwidth-delay product.
It is the capacity in bits of the pipe from the sender to the
receiver and back. To achieve good performance, the receiver's window
should be at least as large as this product. For a transatlantic
gigabit line, with 40 msec round trip time, this window size is 40
megabit or 5 MBytes for each connection.
For time-critical applications, like audio and video, also the
jitter in transmission time is important.
6.6.2 Measuring network performance
The basic loop to improve network performance is:
- Measure the relevant network parameters and performance.
- Try to understand what is going on and where the bottleneck is.
- Change one parameter
The most basic kind of measurement is to start a timer at the
beginning of some activity to see how long it takes, e.g. round trip
time. Other measurements are made with counters to record how often
some event has happened, e.g. number of lost TPDU's. Finally, one is
often interested in knowing the amount of something, e.g. the number
of bytes processed in a given time interval.
There are many potential pitfalls:
- Make sure the sample size is large enough (average a million RTT's)
- Make sure that the samples are representative (no congestions at lunch time)
- Be sure nothing unexpected is going on during the tests (no automatic backup program)
- Caching can wreak havoc (FTP of files still in the disk cache)
- Know what you are measuring (file transfer times depend on: network, OS's used on both sides,
disk or cache speed, drivers, etc.)
- Be careful about extrapolating results (response time as
function of the load)
6.6.3 System design for better performance
Measuring and tuning can improve network performance considerably,
but they cannot substitute for good design.
Some rules of thumb based on experience with many networks, can be
given. They relate to system design, not just network design, since
the software and operating system are often more important than the
routers and interface boards.
1 CPU speed is more important than network speed
In nearly all
the networks, operating system and protocol overhead dominates actual
time on the wire. The biggest problem in running at 1 Gbps is getting
the bits from the user's buffer out on the fiber fast enough and
having the receiving CPU process them as fast as they come in.
2 Reduce packet count to reduce software overhead
Processing a
TPDU has a certain amount of processing per byte (e.g. checksum) and
per TPDU (e.g. header processing), which can be reduced by using
lager TPDU size. In addition to the TPDU overhead, there is also
overhead in the lower layers. Each arriving packet causes an
interrupt which is costly in modern RISC processors: breaking the CPU
pipeline, interfering with the cache, changing the memory management
context, forcing CPU register saving and restoring.
3 Minimize context switches
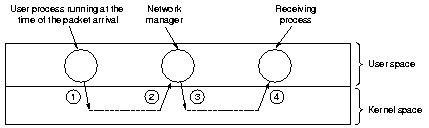 |
Context switches have the same bad properties as interrupts, the worst
being a long series of initial cache misses.
|
4. Minimize copying
It is not unusual for an incoming
packet to be copied 3 to 4 times before the TPDU enclosed in it is
delivered. Thus pass "pointers" or "references"
instead of data. Try to combine copying with checksum calculation, that can
give a speed gain.
5. You can buy more bandwidth but not lower delay.
Putting a
second fiber next to the first one doubles the bandwidth but does
nothing to reduce the delay. Making that shorter requires improving
the protocol software, the operating software or the network
interface, but the speed of light in the fiber remains a limiting
factor.
6. Avoiding congestion is better than recovering from it.
7. Avoid time-outs
6.6.4 Fast TPDU processing
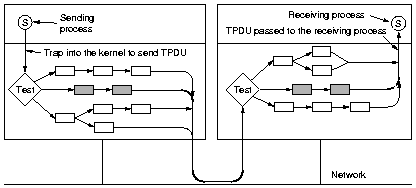
The key to fast TPDU processing is to separate out the normal case
(data transfer in the ESTABLISHED state, no PSH or URG, enough
window space) and handle it separately.
On the receiver side, the connection record for an incoming
TPDU has to be looked up. For TCP these can be stored in a hash
table for which some simple function of the 2 IP and port numbers
is a key. Trying first the last connection, gives a hit rate of more than 90%.
Timer management should be optimized for the case of timers rarely expiring.
In the normal case, the headers of consecutive data TPDU's and NPDU's
are almost the same. They can largely be copied from a stored prototype.
The calculation of a checksum is often combined with copying of
the data. Copying and checksum calculation are so critical for
fast TPDU processing that they are often coded in assembler.
6.6.5 Protocols for gigabit networks
A first problem is the use of 16 or 32 bit sequence numbers. At a
rate of 1 Gbps it takes only 32 sec to send 232 bytes, and
in the Internet packets can live for 120 sec.
A second problem is that communication speeds have improved much
faster than computing speeds, for those who can pay it. In the
70"s, the ARPANET ran at 56 kbps and had 1 MIPS computers. Packets
were 1008 bits, thus there was 18 msec to process a packet, thus
18000 CISC instructions (for a dedicated machine). Compare this to
modern 100 MIPS computers exchanging 4 KB packets over a gigabit
line. There are then 30 µsec to process a packet, or 3000
RISC instructions, which are less powerful than CISC instructions.
A third problem is that the go back n protocol performs poorly
on lines with a large bandwidth-delay product.
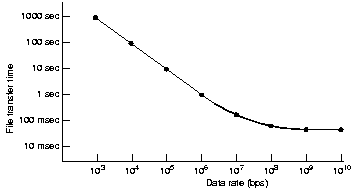
A fourth problem is that gigabit lines are fundamentally
different from megabit lines in that long ones are delay limited
rather than bandwidth limited. The figure shows the time to transfer and acknowledge a 1 megabit file
over a 4000 km line.
A fifth problem is due to new applications. For many gigabit
applications, such as multimedia, the jitter in packet arrival
time is as important as the mean delay itself.
The basic principle that all gigabit network designers should
learn by hart is: "design for speed, not for bandwidth
optimization". Old protocols were often designed to minimize the
number of bits on the wire, frequently by using small fields and
packing them together into bytes and words. Now, not bandwidth but
protocol processing is the problem, so protocols should be designed
to minimize it.
A way to go fast is to build fast network interfaces in hardware.
The difficulty with this is that unless the protocol is very simple,
hardware here just means a pug-in board with its own CPU and
software. To avoid that this coprocessor is as expensive as the main
CPU, it is often a slower chip. As a consequence, much of the time
the fast CPU is waiting for the slow coprocessor to do the critical
work. Furthermore, elaborate protocols are needed between the two
CPU's to synchronize them correctly. Usually, the best strategy is to
make the protocols simple and have the main CPU do the work of the
higher layers.
Due to the relatively long delay loop, feedback should be avoided,
it takes too long for the receiver to signal the sender. One example
is to avoid the delay inherent in the receiver sending windows
updates to the sender, it is better to use a rate-based protocol.
There the sender can send all it wants, provided it does not send
faster than some rate (mean, peak or other parameters) the sender and
receiver have agreed upon in advance. Another example is the slow
start algorithm of TCP, it makes multiple probes to see how much the
network can handle, and with long delays it takes a lot of time and
wastes a large amount of bandwidth. It is better to reserve the
needed resources in advance, making it also easier to reduce jitter.
In short, going to high speeds pushes the design toward connection
oriented operation, or something very close to it.
The header should contain as few field as possible, to reduce
processing time, and these fields should be big enough to do the job
and be "word" aligned, adapted to the characteristics of
modern CPU and memory busses. Big enough means that problems such as
sequence numbers wrapping around while old packets still exists,
receivers being unable to announce enough window space because the
window field is to small, and so on, do not occur.
The header and the data should be separately checksummed. The
header can than be checked before the data is copied to the user
space allowing the data checksum to be done during copying.
Otherwise, if there was an error in the header, the copying might be
to a wrong process.
The maximum data size should be large, permitting efficient
operation even in the face of long delays. It should be possible to
send a normal amount of data along with the connection request. This
is important for connections were only a few messages are exchanged,
like RPC or bank card operations.
Design and implementations of protocols for gigabit networks
should aim at minimizing the processing time for the case that
everything goes right. Minimizing the processing time when an error
occurs is secondary.
Gewijzigd op 18 februari 2003 door Theo
Schouten.