Contents:
After the segmentation of an image, its regions or edges are represented and described in a manner appropriate for further processing.
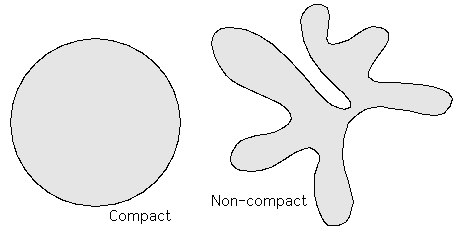
"Shape" is an intrinsic characteristic of 3-D objects or projections thereof. Many other properties, such as edges and surfaces, can be derived from an image. Objects and the naming thereof are primarily defined by shape (and by the function of the object), and not by properties such as color, reflection, surface texture, etc. We are conscious of shape by both outline, which are mainly 2-D data, and by surfaces, which are mainly 3-D structures.
To be useful for further processing the shapes must somehow be represented. This is a tricky but a very interesting problem that becomes more complicated by several factors:
- Shapes are often complex. Color, motion and intensity can be quantified by a small number of well-understood parameters. Shape can often only be explicitly represented using hundreds of parameters. An explicit and complete representation is often not useful for a basic operation such as matching, due to the complexity of the needed arithmetic operations. It is not clear which aspects or features of shape are important for recognition and which can decrease the complexity to a manageable dimension.
-Introspection does not help. A large amount of the human brains seems to work on shape recognition. However, this activity occurs primarily subconsciously. Why is shape recognition (think of faces for example) so easy for a human and shape description so difficult? The fact that we do not have a precise language for shapes (we speak of egg-shaped or ellipse-shaped) already shows how unapproachable it is to make shape processing algorithms or data structures.
- There is little mathematical guidance. Math has traditionally not used "computational geometry". For example, just recently a mathematical definition of a "static field" has been given which coincides with our intuition of set operations on static fields.
- This field of expertise is young, only recently it is useful to represent complex shapes in a manner that a computer can read, edit and graphically represent them. There are no generally accepted representation schemas for all types of shapes; there are several with each their own advantages and disadvantages for certain applications. Algorithms for the manipulation of shapes (for example, how to carry a couch up the stairs) are extremely complex, and still in a rudimentary stage.
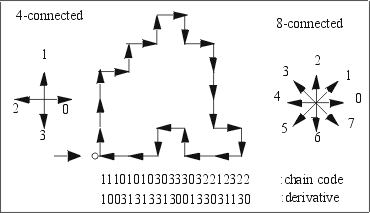
Chain codes are made up of line segments that must lie on a fixed grid with the given set of possible directions. The starting point is given by its coordinates, the other points are reached by passing the grid from to the grid point to grid point. The derivative (0:straight, 1:to the left, 2:to the right) is invariant under rotation and needs both a starting point and a direction.
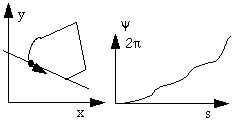
The ![]() -s curve is a generalization of the chain code. Here
-s curve is a generalization of the chain code. Here ![]() is the angle between a static line and a line tangent to the shape, at a certain point along the path s followed from the starting point. Here
too, a starting point and a direction must be given. Straight horizontal lines in
is the angle between a static line and a line tangent to the shape, at a certain point along the path s followed from the starting point. Here
too, a starting point and a direction must be given. Straight horizontal lines in ![]() -s are caused by
straight lines in the x-y, the other straight lines in
-s are caused by
straight lines in the x-y, the other straight lines in ![]() -s by circular arches in x-y. Segmentation
of
-s by circular arches in x-y. Segmentation
of ![]() -s in straight lines thus results in descriptions in x-y in terms of straight lines and circular
arches.
-s in straight lines thus results in descriptions in x-y in terms of straight lines and circular
arches.
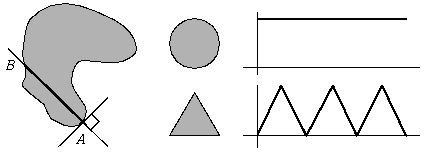
Using "signatures" [fig. 11.5] the distance towards the center is recorded along an angle; a starting position and direction is therefore necessary.
To the side another "signature" method.
 |
An edge, in a digital image given by several consecutive pixels, can each be approximated to any desired precision by a polyline. Finding a polyline approximation for a certain edge is a segmentation problem: finding the corner points or breakpoints that yield a good or a best polyline approximation (according to a certain criterion). Just as with regional segmentation, methods can also be characterized by the concepts "merging" and "splitting". Both concepts can be combined, especially when the number of desired linear segments of the edge is known a priori. Some methods will now be explained briefly. |
If we know that an edge is almost linear, we can specify it by giving its breakpoints. To find these we move along the edge looking at the angle between the two line pieces: the angle between the current point and some points previously visited on the line, and the other angle between the current point and some points on the line ahead. If this angle is larger than a certain threshold value, then we take the current point as a break point.
 |
Tolerance band solutions place two parallel polylines at a distance 2 |
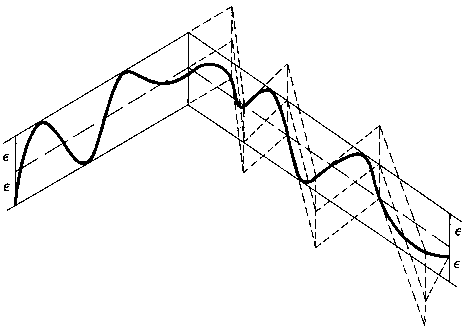 |
This method usually does not find the most economical set of segments. This is a general problem of these "one-pass" algorithms, a new break point is only taken when something went wrong, but it is often desired to take a new break point at an earlier stage. Afterwards one can try to find a better solution by shifting certain break points. |
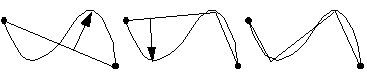 |
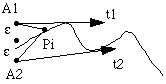
Using split method the segments of a polyline are split up as soon as a certain fit-condition is not satisfied. Take the straight line between the endpoints of a curve and calculate, for each point on the curve between those endpoints, the perpendicular distance to that line. |
If the maximum distance is larger than the tolerance, take the point on the edge with the maximum distance as a new break point. Repeat the above recursively for the two resulting straight lines. The algorithm terminates when the deviation of the edge is less than the tolerance for each line piece. This algorithm must be adjusted for the situation in which a part of the edge runs parallel to a line piece. See [fig. 11.4] for an application of this in a closed contour.
An obvious representation of a region on a grid is an occupation predicator p(x,y) for each grid point that has the value 1 when (x,y) is in the region and 0 otherwise. This spatial occupation-matrix is itself a binary image. Union and intersection can easily (and quickly) be realized using AND and OR operations. This representation occupies a lot of space and is furthermore not even an explicit edge representation.
 |
The y-axis representation is a run-length coding in the y-direction of the spatial occupation-matrix.
There are several possibilities to do this: Union and intersection can be implemented as sorting and joining operations on the RLE rows, with a timescale initially proportional to the number of y rows. This representation is more compact than the occupation-matrix, except when there are long structures in the y-direction. In that case coding in the x-direction may be attractive. Working with a mixed x and y-axis representation is possible, but looses much of its simplicity. |
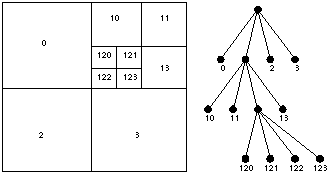 |
Quad trees are another manner of coding the spatial occupation-matrix. The matrix is recursively divided into four parts until every region is composed solely out of a 1 or 0. They can easily be constructed from an intermediate pyramid structure and stored as a linear structure. |
A figure in a 2-D real plane can be represented by its median (skeleton) and the distances from the median to the boundary of the figure. This is an especially suitable representation when the region is composed of thin components.
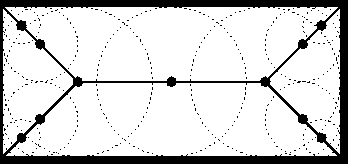 |
The medial-axis of an area A is a set of pairs: |
 |
This skeleton is very vulnerable for noise on the boundary, which can be prevented by smoothing the edge. |
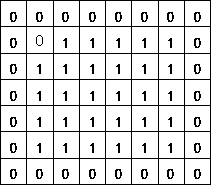
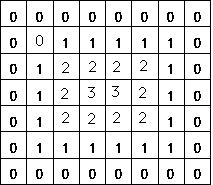
The distance from each pixel in the region to the edge must be taken. The "distance transformation" of a binary image generates an image matrix where each element is an integer or a floating point value equal to the distance from that pixel to the set of zeros. Different distance sizes are possible:
- 4 neighbor: the minimum number of steps required to reach a 0 via 4-neighbors
- 8 neighbor: via 8 neighbors, always smaller or equal to the 4-neighbor distance
- Euclidic: the real Euclidic distance
- approximations (see Borgefors, CVGIP 34(1986)344 )
 |
 |
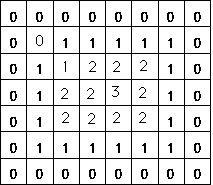 |
From left to right: original image, 4-neighbor DT, 8-neighbor DT.
A parallel algorithm for the 4-neighbor Distance Transformation is:
f(ai,j) = min ( ai-1,j, ai+1,j , ai,j-1 , ai,j+1 ) + 1 if ai,j ![]() 0 else 0
0 else 0
this is repeated in a parallel manner until nothing changes anymore; the amount of repetitions is maximally
the largest distance (the sum of the number of rows and columns).
The serial version is composed of two local operators applied sequentially: f1 applied in a grid scan
in the forward direction ( 1,1 ; 1,2 ; ... 1,m; 2,1....n,m) followed by
f2 in the reverse scan ( n,m ; n,m-1 ; ... n,1 ; n-1,m ; .... 1,1) :
f1(ai,j) = min( ai-1,j + 1, ai,j-1 + 1 ) if ai,j = 1 else 0
f2(ai,j) = min( ai,j , ai+1,j + 1, ai,j+1 + 1) if ai,j0 else 0
(it has not been specified what must happen on the edge of the image).
A DT image is a suitable starting point for certain types of editing on the region, such as determining its thickness (most frequently occurring distance) and its circumference (count the number of ones). Regions can be "peeled":
fn( di,j ) = 0 if di,j =1,2..,n else unchanged
Regions that are thinner than n and for example caused by noise, have then be eliminated. Round regions, for example cells on a biological slide, which partially overlap each other, then become separated from each other. These types of operations are also important in many industrial applications of image processing.
The median axis is then the set of local maximums in the DT image:
(i,j) if none of the following is true: di-1,j , di+1,j , di,j-1, di,j+1 ![]() (di,j +1 )
(di,j +1 )
This is the smallest set of points from which the original binary image can be reconstructed, see also Rosenfeld and Pfaltz, J ACM 13(1966) 471. This can also be done using serial operations:
g1(ai,j) = max( ai,j , ai,j-1 - 1, ai-1,j +1 ) in forward direction and
g2(ai,j) = max( ai,j , ai+1,j - 1, ai,j+1 - 1) in the reverse direction
by applying the grid scan consecutively.
 |
Thinning algorithms, of which there are many, shrink a (binary) region until there is a sort of median left over, which is then used for further processing and editing. The distance information is not stored, therefore the original image cannot be reconstructed. |
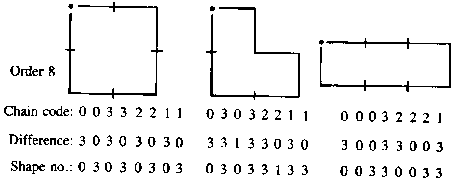 |
Shape numbers of order n, related to their chain code of length n, can be given to edges. The derivative of the chain code with length n is rotated such that the smallest value is attained [fig. 11.11]. This shape number is independent of the position and orientation of the object. |
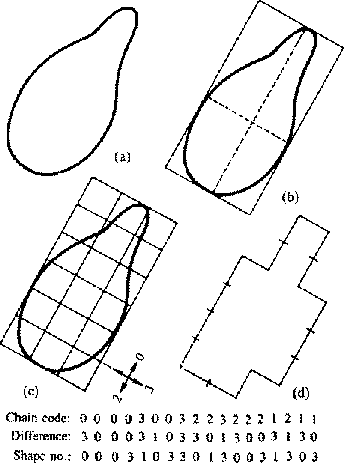 |
It is also independent of the scaling of the object, only dependent on the relative proportions between scale and size of the digitization grid. By changing the size of this grid, "shape numbers" of different orders can be attained. The lower the order, the coarser the digitalization, and the smaller the differences between the shapes become. At the highest order, two shapes still having the same shape number is an indication of equal shapes [see fig. 12.24].  |
The curve ![]() (s)=
(s)= ![]() (s) - 2
(s) - 2![]() s/P (the increasing component has been removed) is used as a basis for the shape description by
Fourier transformation. Some shape parameters are determined by using the amplitudes of the lower order Fourier components. These parameters give an indication of the "pointiness" of the shape.
s/P (the increasing component has been removed) is used as a basis for the shape description by
Fourier transformation. Some shape parameters are determined by using the amplitudes of the lower order Fourier components. These parameters give an indication of the "pointiness" of the shape.
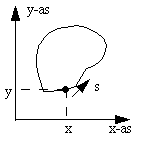 |
A Fourier description can also be determined directly from the shape: x(s) = here |
 |
A shape is usually well described by a small amount of lower order Xk terms [fig. 11.14]. These are not invariant under rotation, translation and scaling, but combinations can be determined that do have those properties. These shape descriptions are not suitable for reconstruction or graphical presentation; for example, a closed shape can become open when a limited amount of coefficients are used. |
Another standard is based on modelling the edge as a thin bent wire.
The normalized bend energy of the wire is: (this is minimal for a circle)
E = 1/P 0![]() P |
P | ![]() (s) | 2 ds with
(s) | 2 ds with ![]() representing the amount of bending.
representing the amount of bending.
This can be calculated from the chain-code, making use of ![]() =
= ![]()
![]() /
/![]() s.
s.
The following also holds:
| ![]() (s) |2 = (
(s) |2 = ( ![]() 2x/
2x/![]() s2) 2 + (
s2) 2 + ( ![]() 2y/
2y/![]() s2) 2
s2) 2
such that E can be determined from the Fourier coefficients: E = ![]() k
(k
k
(k ![]() 0) 4 ( |Xk| 2 + |Yk|
2 )
0) 4 ( |Xk| 2 + |Yk|
2 )
The most basic characteristic of a region is its surface area. This can easily be determined out of a closed polyline ( xi,yi, i=0,...,n-1 ) representation:
0.5 0n-1 (xi+1 yi - xi yi+1 )
For a curve, represented by functions x(s) and y(s) with the length of the arch being s, this becomes:
0P (x
y/
The surface area can also easily be determined from a chain code:
initialize area = 0 and ypos = 0,
walk along the edge and for each element do the following:
code == 0 area = area + ypos
1 ypos = ypos + 1
2 area = area - ypos
3 ypos = ypos - 1
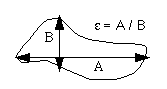 |
The are several units for the stretch or eccentricity. For example, if A is a piece of string of the maximum length, B the string perpendicular to A and also of maximal length, then: |
Other eccentricity units are based on moments:
Mij =
The orientation of a region (the angle between the main axis of the region to the x-axis) and ![]() is
given by:
is
given by:
tan 2= 2 M11 / ( M20 - M02 )
= ( ( M20 - M02 ) 2 + 4 M11) / surface area
 |
A unit for the compactness is the ratio: circumference2 / surface area This is minimal for a circle (4 |
The moments for a continuous 2-dimensonal function are:
mpq = ![]()
![]() xp yq f(x,y) dxdy
xp yq f(x,y) dxdy
µpq = ![]()
![]() (x-x0)p (y-y0)q f(x,y) dxdy with x0 = m10 / m00 and y0 =
m01 / m00
(x-x0)p (y-y0)q f(x,y) dxdy with x0 = m10 / m00 and y0 =
m01 / m00
For a discrete function this then becomes:
µpq = ![]() x
x ![]() y (x-x0)p (y-y0)q f[x,y]
y (x-x0)p (y-y0)q f[x,y]
A uniqueness theorem states that if f(x,y) is continuous and only unequal to 0 in a restricted area, then the series mpq is uniquely determined by f(x,y) and vice versa. From the second and third order moments a set of seven invariant moments can be calculated, which do not change during translation, scaling and rotation of a region [fig. 11.25]. In practice it is very difficult to use these moments for the recognition of objects.
Besides shapes, regions have a certain gray- or color-value distribution named "texture" when there is a certain type of repetition in the structure of it [fig. 11.24].
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
A possible description of texture is: "an image is built up of many interweaved elements". The idea of interweaved elements is closely related to the idea of texture resolution, something like the average number of pixels needed to describe each texture element. If this is large enough, one can try to describe the individual elements with some detail and especially their positions. When this number comes close to 1, it is more difficult to characterize individual elements. Combined together these result in less individual spatial patterns. Statistical methods are then used to describe the distribution of the gray levels in the image.
Textures can be hierarchical, different levels correspond to different recording resolutions. When we look at a brick wall closely, we see that each brick has color or intensity variations which we can describe using a statistical model. If we look at the wall at a larger distance, then we can recognize half or whole bricks and describe the location and orientation of those bricks relative to each other. At an even larger distance each individual brick will only be several pixels large and is not suitable for geometric descriptions, we must then migrate to a more suitable statistical model.
 |
Texture is almost always a characteristic bound to a region. It can therefore be used to determine the properties of hte region, such as the orientation with respect to the viewing direction, or the distance, to the camera: the so called texture gradient techniques. |
Statistical pattern recognition occupies itself with the classification of (individual occurrences) patterns. It is a separate field of expertise and has many application possibilities. Here we use an approximation to classify the texture of a region using a set of given textures. Over the last few years neural networks have been used more and more for such classification problems.
A basic notation in pattern recognition is the "feature vector", v = (v1,...,vn), with which the relevant properties of a pattern are represented in a small n-dimensional Euclidic space. The feature vector is calculated out of available measurement data.
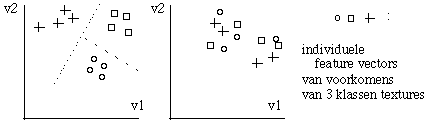 |
With effective features the different classes can be divided into well-defined sub-spaces. The vectors of instances of a certain class lie close to each other and are well separated from vectors in other classes. See also fig. 12.1. |
Suitable features and a good partition of the feature space can be achieved by:
There are many methods for the classification of a newly measured point in the feature space. An example is the "nearest mean" or "minimum distance" method, see fig. 12.6. Here every texture class i has a center point ci in the n-dimensional feature space. It is determined by training, for example by averaging the training samples of each class. Add the new point, for which the Euclidic distance || v - ci||2is minimal, to class i.
Using the "nearest neighbour" classifier we are interested in the training samples which lie the closest to the new point, and we take that class as the class of the new point. This can require a lot of calculation time. With the "condensed nearest neighbor" classification we are only interested in the training samples that lie on the edge of each class subspace. Naturally, there are many possibilities for the condensation of training samples.
With the "k-Nearest Neighbour" (kNN) classifier we are interested in the k training samples that are the closest to the new point. We take the class with less than the k (e.g. k = 5) points and occurring most frequently, as that of the new point.
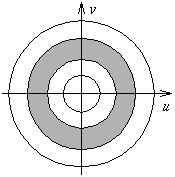 |
When texture is spatially periodic, the energy spectrum of it ( |F(u,v)|2 ) shall show peaks at corresponding frequencies (see fig. 11.24). We can find these peaks directly from the energy spectrum when the local maximums are clearly separated. However, if these peaks are not clear or do not yield the desired distinction between a given set of textures, then we can use the energy distribution over the frequency plane. The feature vector is given by the energy per segment of the spectrum: |
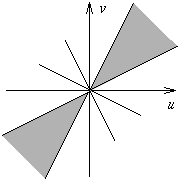 |
When a texture has a direction preference, thus the orientation of lines or figures in a certain direction, then the energy spectrum shall also show a clustering in that direction. In that case, it would be best for the feature vector to measure energy densities in a certain direction: V To make a choice out of a given set of textures, we must include features such as the radius and tangent. |
We can also apply a similar sort of energy approximation to the spatial image itself. The advantage is that the basis is not the Fourier basis (cos and sin waves) but rather a more suitable set of basic texture patterns. An example of Laws (1980):
 |
 |
The m-dimensional feature space is then divided up into regions. Each region is labeled with a certain class of textures. Each pixel then obtains the texture class of the region where its feature vector lies, for example with the "nearest mean" method. To the left you see a collage of 3 textures, to the right the result of the classification of the pixels. |
An alternative, that which Laws used, is to construct about 25 5*5 convolution kernels from 5 one-dimensional kernels. This is done by the convolution of one horizontal 1-D kernel with one vertical 1-D kernel:
L5 = [ 1 4 6 4 1 ] (Level)
E5 = [ -1 -2 0 2 1 ] (Edge)
S5 = [ -1 0 2 0 -1 ] (Spot)
W5 = [ -1 2 0 -2 1 ] (Wave)
R5 = [ 1 -4 6 -4 1 ] (Ripple)
If the direction of the texture is not of importance, the features can be averaged to a set of 14 features that remain invariant under the rotation of the texture.
Spatial Gray Level Dependence (SGLD) matrices (sometimes also referred to as co-occurrence matrices) are one of the most popular sources of texture features, see also chapter 11.3.3 on page 668. The definition of the SGLD matrix is:
S(i,j,d,![]() ) : the number of locations (x,y) in the image f with f(x,y) =
i and f(x + d cos
) : the number of locations (x,y) in the image f with f(x,y) =
i and f(x + d cos![]() , y + d sin
, y + d sin![]() ) = j;
) = j;
i and j are gray values, where usually the complete resolution of the image is not used: minI, minI+![]() I,...., maxI
I,...., maxI
d the distance, smaller than the texel size (a small number of pixels)
![]() usually restricts itself to a small number of angles (steps of 45°)
usually restricts itself to a small number of angles (steps of 45°)
For many textures the reversal of the direction is not relevant: S'(d,![]() ) = 1/2 ( S(d,
) = 1/2 ( S(d,![]() ) + S(d,
) + S(d,![]() +
+![]() ) )
) )
Some features which can be derived from the SGLD matrix are:
E(d,
H(d,
I(d,
A summation over several d and ![]() s can also be taken. These features have no relationship with "rough" or
"smooth" which people typically use to describe textures.
s can also be taken. These features have no relationship with "rough" or
"smooth" which people typically use to describe textures.
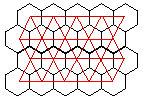 |
With regular models the texels are placed in a plane in an ordered manner. The black hexagonal tiles divide the plane into regular hexagonals. This regular tessellation of a plane is often indicated by (6,6,6) because the three polygons that surround a vertex have 6 edges. More important than the texels is the division of the plane, which describe the positioning of the texels. |
The centers of the tiles divide the plane into equilateral triangles which have been indicated using red. This is a (3,3,3,3,3,3) division, every vertex is surrounded by 6 polygons, each with 3 edges. Another regular division is (4,4,4,4). There are also semi-regular divisions of the plane, for example (4,8,8), (3,6,3,6), (3,4,6,4), (3,3,3,4,4), (3,3,4,3,4), (3,3,3,3,6), (3,12,12) and (4,6,12).
Grammatical models describe how patterns are generated by the application of rewriting rules on a small number of symbols, which are related to texels. For generated textures to appear as real ones, often probabilities are credited to the rules: stochastic grammars. There is no unique grammar for a given texture, often resulting in an infinite amount of possibilities for rules and symbols.
A shape-grammar is defined as a 4-tuple: <Vt ,Vm ,R, S> where:
- Vt is an infinite set of shapes, terminal shape elements
- Vm is a finite set of non-terminal marking shapes, disjoint of the set of Vt : Vt ![]() Vm =
Vm = ![]()
- R is the finite set of rules: ordered pairs (u,v) with u a shape consisting of elements from Vm+ and v a shape consisting of an element from Vt* combined
with an element from Vm*.
- S is the starting symbol (such as a v-shape)
Here the elements are formed out of the set Vt+ by finitely rearranging one or more of the elements of Vt. Each element and its reflected shape can be used several
times in each position, orientation or scale. And Vt* is equal to Vt+ ![]()
![]() .
.
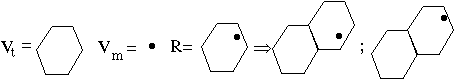 |
Here is a simple example of the many ways in which a hexagonal texture positioning can be generated. |
A more complicated example is the generation of "reptile-skin" texture, which can be portrayed as a (3,6,3,6) positioning with local deformations and extra lines. The rules which determine whether normal continuation or addition of a new line is necessary are executed according to certain probabilities, such that more or less regular textures are generated.
When applying the rules in the inverse direction, textures should be recognizable. We must concentrate on the variation in the shapes that either exist in real textures or are caused by the portrayal process. For this reason, in practice, textures are practically never recognized by parsing.
Updated on April 4st 2003 by Theo Schouten.